引言
在自然语言处理(NLP)领域,Transformer模型自2017年提出以来,凭借其强大的并行处理能力和自注意力机制,迅速成为各类NLP任务的主流架构。本文将深入解析Transformer模型的代码实现,并探讨其在实际应用中的具体用法。
Transformer模型概述
Transformer模型由Vaswani等人提出,旨在解决传统序列到序列模型(如RNN、LSTM)中的长期依赖问题。它摒弃了循环结构,完全基于自注意力机制进行序列建模,从而实现了高效的并行计算。
Transformer模型结构
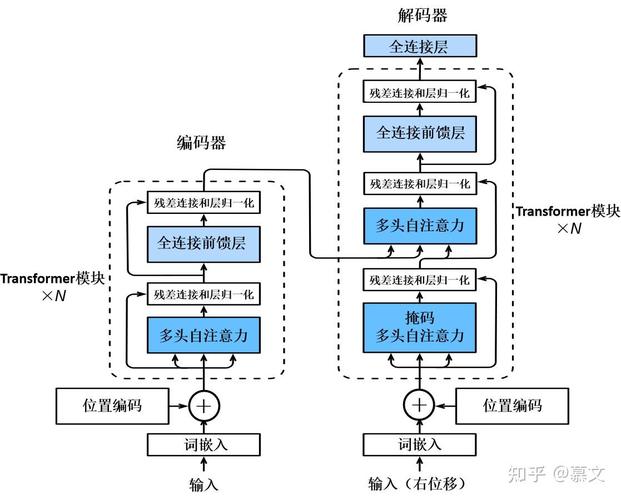
Transformer模型主要由编码器(Encoder)和解码器(Decoder)两部分组成,每部分包含多个相同的层。每层又由自注意力机制(Self-Attention)和前馈神经网络(Feed Forward Network)组成。
编码器(Encoder)
- 输入嵌入(Input Embedding):将输入序列转换为向量表示。
- 位置编码(Positional Encoding):为输入向量添加位置信息,以解决Transformer模型本身无法捕捉序列顺序的问题。
- 多个相同的编码器层:每层包含自注意力机制和前馈神经网络。
解码器(Decoder)
- 输入嵌入和位置编码与编码器相同。
- 多个相同的解码器层:每层除了自注意力机制和前馈神经网络外,还包含一个额外的编码器-解码器注意力机制(Encoder-Decoder Attention),用于将编码器的输出作为输入。
Transformer代码实现
下面我们将使用Python和PyTorch框架来实现一个简单的Transformer模型。
导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F定义位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]定义自注意力机制
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Scaled Dot-Product Attention
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys]) / (self.embed_size ** (1 / 2))
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy, dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out定义前馈神经网络
class FeedForward(nn.Module):
def __init__(self, embed_size, ffn_dim):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(embed_size, ffn_dim)
self.fc2 = nn.Linear(ffn_dim, embed_size)
def forward(self, x):
return self.fc2(F.relu(self.fc1(x)))定义Transformer层
class TransformerLayer(nn.Module):
def __init__(self, embed_size, heads, ffn_dim, dropout):
super(TransformerLayer, self).__init__()
self.self_attn = SelfAttention(embed_size, heads)
self.feed_forward = FeedForward(embed_size, ffn_dim)
self.layer_norm1 = nn.LayerNorm(embed_size)
self.layer_norm2 = nn.LayerNorm(embed_size)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
def forward(self, x, mask):
x = self.layer_norm1(x + self.dropout1(self.self_attn(x, x, x, mask)))
x = self.layer_norm2(x + self.dropout2(self.feed_forward(x)))
return x定义Transformer模型
class Transformer(nn.Module):
def __init__(self, embed_size, src_vocab, trg_vocab, heads, num_encoder_layers, num_decoder_layers, ffn_dim, dropout):
super(Transformer, self).__init__()
self.model_type = 'Transformer'
self.src_word_embedding = nn.Embedding(src_vocab, embed_size)
self.trg_word_embedding = nn.Embedding(trg_vocab, embed_size)
self.positional_encoding = PositionalEncoding(embed_size)
self.encoder_layers = nn.ModuleList(
[TransformerLayer(embed_size, heads, ffn_dim, dropout) for _ in range(num_encoder_layers)]
)
self.decoder_layers = nn.ModuleList(
[TransformerLayer(embed_size, heads, ffn_dim, dropout) for _ in range(num_decoder_layers)]
)
self.fc_out = nn.Linear(embed_size, trg_vocab)
def forward(self, src, trg, src_mask, trg_mask):
src = self.src_word_embedding(src) * math.sqrt(self.src_word_embedding.embedding_dim)
trg = self.trg_word_embedding(trg) * math.sqrt(self.trg_word_embedding.embedding_dim)
src = self.positional_encoding(src)
trg = self.positional_encoding(trg)
enc_output = src
for layer in self.encoder_layers:
enc_output = layer(enc_output, src_mask)
dec_output = trg
for layer in self.decoder_layers:
dec_output = layer(dec_output, trg_mask, enc_output, src_mask)
output = self.fc_out(dec_output)
return output实战应用
在实际应用中,我们可以使用上述Transformer模型来完成各种NLP任务,如机器翻译、文本摘要、情感分析等。以下是一个简单的机器翻译示例:
数据预处理
在进行模型训练之前,我们需要对源语言和目标语言的数据进行预处理,包括分词、构建词汇表、生成词嵌入等。
模型训练
使用预处理后的数据对Transformer模型进行训练。训练过程中,我们可以采用交叉熵损失函数和Adam优化器来优化模型参数。
模型评估与推理
训练完成后,我们可以使用测试集对模型进行评估,并在实际应用中进行推理。推理时,将输入序列传递给模型,即可得到输出序列的预测结果。
结论
Transformer模型凭借其强大的并行处理能力和自注意力机制,在NLP领域取得了显著的成功。通过本文的详细解析和实战应用示例,相信读者已经对Transformer模型有了更深入的理解。未来,随着技术的不断发展,Transformer模型将在更多领域发挥重要作用。