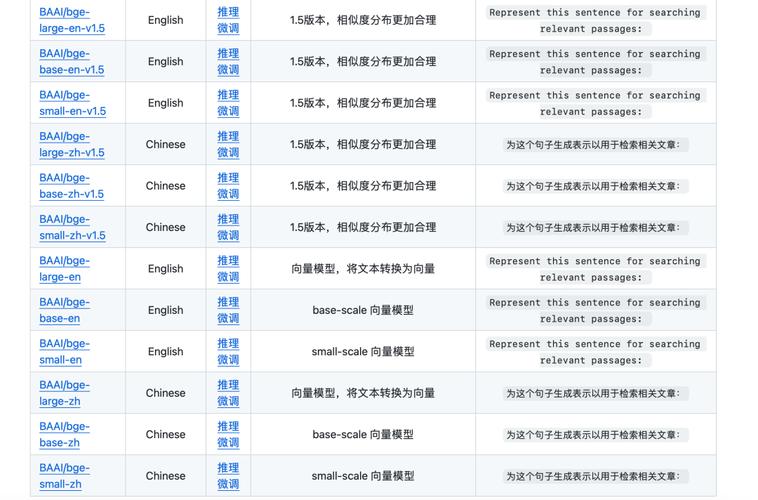
embedding模型排名:深度解析与应用场景对比
在自然语言处理(NLP)和机器学习领域,embedding模型是理解文本数据、捕捉词汇或实体间复杂关系的关键技术。随着技术的不断进步,各种embedding模型层出不穷,它们在不同任务上的表现也各有千秋。本文将详细探讨几种主流的embedding模型,并对其进行排名与对比分析,以帮助读者更好地理解这些模型的特点与应用场景。
1. Word2Vec
简介:Word2Vec是Google于2013年推出的一个开源工具包,用于计算词向量。它基于分布式假设,即相似的词在向量空间中也应该相近。
特点:Word2Vec包括CBOW(Continuous Bag of Words)和Skip-gram两种模型,前者根据上下文预测目标词,后者则相反。它能够有效捕捉词汇间的语义关系,且计算效率高。
应用场景:适用于文本分类、情感分析、命名实体识别等任务。
2. GloVe
简介:GloVe(Global Vectors for Word Representation)是由斯坦福大学于2014年提出的一种词向量表示方法。
特点:GloVe结合了全局统计信息(如共现矩阵)和局部上下文信息,通过最小化损失函数来学习词向量。它在捕捉词汇间的语义和语法关系上表现优异。
应用场景:适用于机器翻译、文本相似度计算等任务。
3. FastText
简介:FastText是Facebook AI Research于2016年推出的一种快速文本分类工具,同时也提供了一种有效的词向量表示方法。
特点:FastText能够处理未登录词(OOV)问题,通过将单词分解为字符n-gram来学习词向量。这使得它在处理形态丰富的语言时表现尤为出色。
应用场景:适用于多语言文本处理、社交媒体分析等任务。
4. BERT
简介:BERT(Bidirectional Encoder Representations from Transformers)是Google于2018年提出的一种预训练语言表示模型。
特点:BERT采用了双向Transformer编码器结构,能够同时考虑上下文信息。通过大规模语料库的预训练,BERT在多项NLP任务上取得了显著突破。
应用场景:适用于问答系统、情感分析、文本摘要等复杂NLP任务。
5. GPT系列
简介:GPT(Generative Pre-trained Transformer)系列模型由OpenAI推出,包括GPT-1、GPT-2和GPT-3等版本。
特点:GPT系列模型采用自回归语言模型结构,能够生成连贯的文本。随着模型规模的增大,GPT系列在文本生成、对话系统等领域展现出强大的能力。
应用场景:适用于自动写作、聊天机器人、代码生成等任务。
排名与总结
需要注意的是,上述排名并非绝对,因为不同embedding模型在不同任务上的表现受多种因素影响,如数据集大小、任务复杂度等。在实际应用中,应根据具体需求选择合适的模型。
总的来说,Word2Vec和GloVe是传统embedding模型的代表,适用于简单的NLP任务;FastText则在处理多语言文本时具有优势;BERT和GPT系列作为预训练语言模型的代表,在复杂NLP任务上表现卓越。随着技术的不断发展,未来还将涌现出更多优秀的embedding模型,为NLP领域带来更多的可能性。
参考文献
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
- Pennington, J., Socher, R., & Manning, C. D. (2014). GloVe: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
- Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2017). Enriching word vectors with subword information. Transactions of the Association for Computational Linguistics, 5, 135-146.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) (pp. 4171-4186).
- Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.